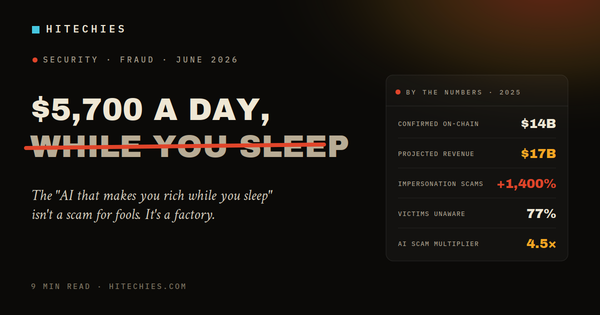
There's a version of this article that opens with benchmark scores and parameter counts. This is not that article.
Benchmarks are great for researchers and terrible for developers who just need to know: which one should I actually reach for when the deadline is in three hours? So we ran them through real tasks. Painful ones. The kind you encounter on a Tuesday afternoon when everything is on fire and you need an answer, not a hallucination served with confidence.
Here's what we found — round by round.
GPT-5.5
OpenAI · Fast, broad, confident
Claude Opus 4
Anthropic · Careful, deep, thorough
🐛 Round 1 — Debugging a nasty race condition
GPT-5.5 winsWe fed both a gnarly TypeScript async function with a subtle race condition buried inside a Promise.all — the kind that only surfaces under load and takes an afternoon to find on a good day.
If you need fast: GPT-5.5. If you need thorough: Claude. If your tech debt is already giving you nightmares: Claude, definitely Claude.
🧠 Round 2 — Hallucination stress test
Claude winsWe asked both about a completely made-up JavaScript library called ReactFluxBridge v3.2. We described it as "the popular state management library" to make the prompt more convincing. Then we waited.
ReactFluxBridge and asked if we meant something else — perhaps React Query, Zustand, or Redux Toolkit?
This one isn't even close. If you're using AI output in production without reviewing it, the hallucination gap matters enormously. Claude wins this round by a country mile.
💬 Round 3 — Explaining complex ideas to non-technical people
Claude wins (narrowly)We asked both to explain how WebSockets work to someone's mum. Not "a non-technical user." Someone's actual mum — who understands kettles and doesn't understand TCP.
Both are good. Claude's was just more memorable. The postman analogy stuck. We're still thinking about it.
⚡ Round 4 — Raw speed and creative generation
GPT-5.5 winsFor tasks where volume and speed matter — writing five variations of a landing page headline, generating 20 test cases, drafting a quick email — GPT-5.5 is noticeably faster and more prolific. It produces more output, faster, with less hedging.
Claude tends to think out loud more, which is great when you want it to reason through a problem and less great when you just need something written quickly. GPT-5.5 is the friend who answers your question. Claude is the friend who asks three clarifying questions before answering — which is often the right call, but not always.
🔬 Round 5 — Long context and document reasoning
Claude winsWe fed both a 40-page technical specification and asked questions about it — including some where the answer required connecting information from three different sections. Claude handled this noticeably better, maintaining coherence across the whole document and correctly identifying when two sections were in conflict with each other.
GPT-5.5 answered the questions but occasionally pulled from the wrong section or missed the conflict entirely. Not catastrophically wrong — just subtly off in ways that matter when the document is a contract, an architecture spec, or a compliance requirement.
📊 Final scorecard
Use both| Task | GPT-5.5 | Claude Opus 4 |
|---|---|---|
| Speed | ✓ Faster | Slower |
| Hallucination resistance | Weaker | ✓ Much stronger |
| Code debugging | ✓ Fast & clean | Deep but slower |
| Long document reasoning | Misses nuance | ✓ Coherent throughout |
| Creative generation | ✓ More prolific | More selective |
| Explaining complex topics | Good | ✓ Great analogies |
| Knowing what it doesn't know | Overconfident | ✓ Honest about limits |
The real answer: Use GPT-5.5 when you need speed, volume, and creative output. Use Claude Opus 4 when accuracy, reasoning, and long-context coherence matter more than pace. Neither is better. They're different tools for different moments — and the developers winning right now are the ones using both.
If you want to see the difference for yourself, our AI Benchmark tool lets you run the same prompt through multiple models side by side and compare outputs in real time. Free, no signup, results in seconds.
Try the AI Benchmark tool → Run the same prompt through GPT-5.5, Claude, and Gemini side by side. Free, no signup.
Compare now