A research firm maxed out every Claude and ChatGPT tier and the internet decided your $200 plan “costs OpenAI $14,000.” That number is misleading in a specific, important way. Here is the real math, why the subsidy is real anyway, and the part nobody can actually predict.
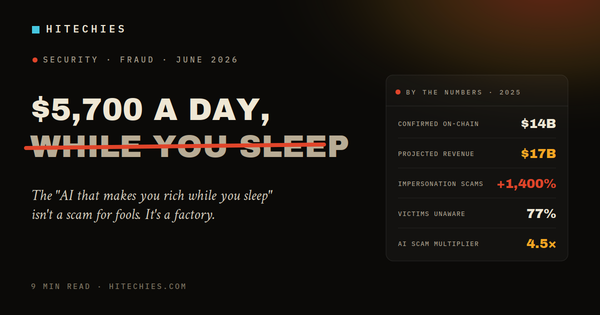
Two weeks ago the research firm SemiAnalysis ran an experiment worth understanding properly, because most of the coverage mangled it. They bought every subscription tier from OpenAI and Anthropic, from the $20 entry plans to the $200 top tiers, then ran long-horizon coding and agent-style tasks until they hit each plan’s weekly usage cap. They counted the tokens consumed and converted them to what the same work would cost at each provider’s published API rates.
The headline figure that escaped into the wild: a fully exhausted $200/month ChatGPT Pro plan represents about $14,000 of API-priced usage, and Claude Max 20x, also $200, lands around $8,000. From there a hundred outlets ran some version of “your $200 plan costs OpenAI $14,000.”
That sentence is wrong, and the way it is wrong is the most interesting thing about the whole story. So let me take the number apart, rebuild it honestly, and then make the case that the conclusion mostly survives anyway.
API price is not cost
The $14,000 is API-equivalent value, not cost. It is what you would have paid OpenAI if you had bought that exact usage at retail API prices. Retail API prices are not what it costs OpenAI to serve a token. They include gross margin, infrastructure, support, R&D recovery, and everything else a price has to carry. Treating the API sticker as the lab’s cost is like saying a venti latte “costs Starbucks $6.”
We can actually estimate the real gap, because both companies have started disclosing inference margins. According to The Information’s reporting and SemiAnalysis’s own infrastructure work, Anthropic’s inference margin is now around 70%, up from roughly 38% a year ago, and OpenAI’s compute margin climbed to a similar neighborhood through 2025. A 70% margin means the actual compute cost of serving a token sits near 30% of its API price.
Run that through the scary numbers and they shrink fast. The $14,000 of API value is closer to $4,000–$4,500 of real compute cost. The $8,000 of Claude usage is closer to $2,500. Still a lot more than the $200 the customer paid, but not the apocalyptic figure that went viral.
SemiAnalysis already knew API price isn’t cost. In their own worst-case margin example they explicitly assumed a 75% API gross margin, then calculated that a maxed heavy user on Claude’s $200 plan generates roughly a −900% gross margin for Anthropic. That −900% is built on cost being a quarter of API price, not equal to it.
The people quoting “$200 costs them $14,000” were misreading the source, not just oversimplifying it. The defensible claim is narrower and still uncomfortable: at full utilization a single $200 seat can cost a lab a few thousand dollars in actual compute, roughly 15–20× the price. Real, but not $14,000.
And that is the whole game
Before this becomes another doom piece, the second correction. The $14,000 ceiling describes someone hammering the most expensive reasoning modes continuously, generating hours of video, and running agents around the clock for a month. Almost nobody is that person. SemiAnalysis measured the ceiling on purpose, because flat-rate pricing has to survive its worst case, but the ceiling is not the average.
Most $200 subscribers live down in single-digit utilization, where the same plan throws off a healthy margin. SemiAnalysis’s own framing makes this concrete: the Claude Max seat that loses 900% at full tilt produces a +90% gross margin at 1% utilization. The entire model is a bet on distribution, the same bet a gym makes on members who quit in February, or Costco makes on the $1.50 hot dog you buy alongside a pallet of paper towels. A long tail of light users subsidizes a short head of heavy ones, and the blended average lands in the black.
“Heavy users cost more than they pay” has been true of flat-rate pricing since flat-rate pricing existed. It has rarely been fatal.
Why the subsidy is real anywayThe financials don’t need SemiAnalysis
If the $14,000 is wrong and the median user is profitable, why claim there is a subsidy at all? Because the corroborating evidence comes from somewhere else entirely, and it is hard to wave away.
The Information reported that Anthropic’s overall gross margin for 2025 landed around 40%, ten points below its own optimistic target, after inference costs came in 23% higher than projected. OpenAI’s gross margin fell from 40% to 33% over the same period, against a 46% forecast. Anthropic’s gross margin in 2024 was negative 94%. As recently as March 2026, Anthropic’s CFO stated in a sworn affidavit that the company had taken in north of $5 billion in revenue while spending around $10 billion on inference and training. OpenAI spent roughly $1.70 for every dollar it earned in 2025 and does not turn cash-flow positive until 2030 on current estimates.
Then there is the layer above the labs, where there is no light-user tail to hide behind. One investment firm calculated that Cursor was paying Anthropic about $650 million a year while generating roughly $500 million in revenue, a negative 30% gross margin, which is precisely why Cursor went and trained its own model to escape the bill. Microsoft reportedly lost more than $20 per user per month on GitHub Copilot at its $10 price point. Replit moved from flat task pricing to effort-based pricing that can hit $2 a task, passing the variability straight to users.
None of that depends on the SemiAnalysis study. It is a consistent picture across company disclosures, court filings, and the unit economics of the firms reselling these models. That is a subsidy. The SemiAnalysis experiment just put a vivid, slightly overcooked number on a thing the financials already implied. We walked through the investor-side version of this in Anthropic at $900 Billion: the IPO questions nobody is asking.
What actually changedThe human got removed from the loop
The reason any of this is newly interesting is that the usage pattern mutated. A ChatGPT exchange in 2023 ran maybe 500 to 2,000 tokens, and it was bounded by a person typing and reading. That human speed limit is what made flat pricing safe in the first place. You can only consume so much when your hands are the bottleneck.
Agents removed the bottleneck. SemiAnalysis pegs a typical agent job at around 96,000 tokens before it returns an answer, more than the text of The Great Gatsby spent to tell you your tests pass. Goldman Sachs estimated agentic workflows could lift token demand by 24×; the heaviest scenarios run higher. The price stayed flat while the thing being priced started running at machine speed instead of human speed.
This is the real risk to the distribution bet, and it is worth stating precisely because it is easy to overstate. The danger is not that heavy users exist. It is that agentic workflows raise the floor of normal usage. When the default way to use a coding agent is to hand it a task and walk away, idle seats become busy seats, and the long tail that subsidizes everything gets compressed from below. That is a slow erosion, not a cliff. It is also exactly the kind of slow erosion that does not show up until a budget cycle forces someone to notice.
The Uber number, with its caveatHigh spend is not automatically a loss
Uber’s CTO told The Information the company burned through its entire 2026 AI budget in four months, driven by Claude Code adoption inside engineering jumping from 32% to 84%, at $500 to $2,000 per engineer per month. They now run an internal dashboard so engineers can watch their spend.
The honest reading is narrower than the doom version. We do not know what that spend replaced, what it produced, or what share of Uber’s engineering budget it represents. If $2,000 a month of Claude Code makes an engineer meaningfully more productive, that is a bargain, not a crisis. The signal in the Uber story is not “AI is too expensive,” it is that the spend grew fast enough to blow through a budget set only months earlier. The surprise is the data point. The productivity offset is the part nobody has measured yet — a gap we dug into in $200/month per developer, and most companies cannot explain what they are getting.
The prediction everyone makesWhy I only half-believe it
Here is where reported fact ends and interpretation begins, so I will mark the line clearly. Everything above is sourced. What follows is a read, and reads can be wrong.
The tempting conclusion is: subsidies end, so prices go up, so enjoy it while it lasts. I think the direction is right and the confidence is unearned, because there is a second force pulling the other way just as hard. Inference is getting dramatically cheaper. Both labs’ inference margins roughly doubled in a year because cost per token is falling, not because they hiked prices. Enterprise data cited by Ramp shows average cost per million tokens dropping from about $10 to $2.50 in a single year. NVIDIA’s Rubin platform targets a 10× inference cost cut; OpenAI’s first custom inference chip aims to roughly halve serving costs; Anthropic committed $21 billion to Google TPUs partly to control unit costs.
So the actual question is not “will the subsidy end.” It is a race: are costs falling faster than agentic demand is rising? If unit costs drop faster than agents inflate consumption, margins expand and the flat plan survives more or less intact. If demand outruns efficiency, the squeeze materializes. I do not know which wins, and anyone who tells you they are certain is selling something.
There is also a constraint that makes dramatic repricing genuinely hard: competition. OpenAI is reportedly weighing token price cuts to win developers from Anthropic, not hikes. If any one lab jacks up prices, customers route around it, increasingly to open-weight Chinese models like DeepSeek V4, which one startup switched to wholesale, claiming it matched Claude Sonnet for their workload at a fraction of the cost. Competition caps pricing power. That is the strongest reason to doubt the simple “prices go up” story.
If I had to bet, it is not on price hikes to existing plans. Raising the sticker on something people already pay for generates immediate, organized backlash. The quieter move, already visible, is to leave current plans alone and gate new capability. GitHub Copilot switched in June 2026 from flat-rate to usage-based credits, with some customers reporting effective increases up to 100× once real consumption got metered. Anthropic began billing agent tools and third-party harnesses separately at API rates in mid-June, and has been quietly tightening Claude Code weekly rate limits since mid-2025. None of those were headline price increases. All of them reprice the exact behavior that breaks the unit economics.
A gym can’t throttle your bench press. These providers can rate-limit you, queue you, swap the model under you, or meter your agents — and already do all four.
That is where the gym-and-hot-dog analogy quits on us, and the difference is the whole point. The flat subscription is not a fixed promise the way a gym membership is. It is a dial the provider can turn, which is precisely why I would expect dials, not price tags, to do the adjusting.
What this means if you build with these toolsTreat the price as provisional
Strip out the viral number and the honest version is still useful, which is the test of whether a thesis was real or just loud. Today’s heavy-user pricing is subsidized by some mix of investor capital, falling inference costs that have not fully reached you, and a light-user majority covering your bill. Some of that is permanent-ish (costs really are falling) and some is temporary (capital and cross-subsidy are not infinite). You do not get to know the mix in advance.
The move that is correct under every scenario is to treat the model layer as swappable. Do not hard-wire your product or your team’s workflow to one vendor’s specific flat plan as though today’s price is a law of nature. Route easy work to cheap models and reserve frontier models for the tasks that need them — that routing can cut costs as much as 95%, and as one researcher put it, you do not need a model that understands quantum gravity to reformat a CSV. If you are still deciding which model anchors which task, our honest breakdown of GPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro is built for exactly that call.
Build for portability and the worst case is you shrug and switch. Hard-code to one provider’s subsidized tier and the worst case is a Copilot-style 100× surprise you cannot route around. The cheap era is real, the $14,000 version of it is fiction, and the only safe assumption is that the price you pay today is provisional. Use the tools hard. Just do not pour your foundation on a number that is still being subsidized into existence.